I deleted ~1,000 blog posts for a few hours and then restored them.
As you can see, the site speeds up significantly when the posts are removed:

Is this the expected behavior? Anything I can do to speed up the site while keeping the ~1,000 posts?
@superhua, Without knowing what you are measuring, it’s hard to tell if your site is showing expected behaviour. Please provide us more information about the request you are measuring.
Btw, did you have a chance to read the docs on Permance & Caching?
Thank you.
The graph is from Uptime Kuma and displays a simple response time.
I’ve read the Performance and Caching material and am using the default caching.
From system.yaml:
cache:
enabled: true
check:
method: file
driver: auto
prefix: g
purge_at: '0 4 * * *'
clear_at: '0 3 * * *'
clear_job_type: standard
clear_images_by_default: true
cli_compatibility: false
lifetime: 604801
gzip: true
allow_webserver_gzip: false
redis:
socket: null
password: null
database: null
server: null
port: null
memcache:
server: null
port: null
memcached:
server: null
port: null
twig:
cache: true
debug: false
auto_reload: true
autoescape: false
undefined_functions: true
undefined_filters: true
safe_functions: { }
safe_filters: { }
umask_fix: false
and
flex:
cache:
index:
enabled: true
lifetime: 60
object:
enabled: true
lifetime: 600
render:
enabled: true
lifetime: 600
An older post suggests that 1,000 pages was the limit. However, with Grav 1.7+, this doesn’t seem like an issue. (We’re on Grav 1.7.48.)
I’m trying to figure out why removing these posts would have such a marked difference in the responsiveness of the site.
The graph is from Uptime Kuma and displays a simple response time.
Again, still not sure what kind of request you are measuring…
Anyway, I did my own benchmark:
for f in {1..1000}
do
mkdir "user/pages/01.blog/blog-item$f"
cat "user/pages/01.blog/the-urban-jungle/item.md" > "user/pages/01.blog/blog-item$f/item.md"
done
$ bin/grav cachecontent:
items: '@self.children'
limit: 6
order:
by: date
dir: desc
pagination: true
url_taxonomy_filters: true
pagination: true
As said, I’m not sure what your request is about…
is it 4-5 sec when have 1000 pages ? if it measures ping like sending signal and taking back a response and calculates time spent between two, that is too much i think. it would be normal if it was total of all 1000 pages maybe since it will be like 4 ms for each. if that is the case i wouldnt use that app all time because it would effect performance with not equal benefit imo, just testing like you do would be good.
if it is a page’s loading time, i dont think 1000 pages should effect each other since they should be cached separately.
as @pamtbaau said, we would like to have more information, have a nice day ![]()
Thanks for taking the time to do that!
Your results are solid; I’ll need to keep digging on my end to see what is causing the slow down.
The request that Uptime Kuma measures is the server response time / the HTTP request for the site. I’m not sure of the details beyond that ![]() , but the site definitely slows down when there are many blog posts present.
, but the site definitely slows down when there are many blog posts present.
Thanks again.
@superhua, It would be helpful if you could provide more information:
---
title: 'Page Title'
content:
items:
- '@self.children'
limit: 5
order:
by: date
dir: desc
pagination: true
url_taxonomy_filters: true
show_sidebar: false
feed:
limit: 10
---
We’re running the following plugins:
I’ll need to clone the site and disable non-default plugins to see if that makes any difference.
We’re running a slightly-modified Quark theme.
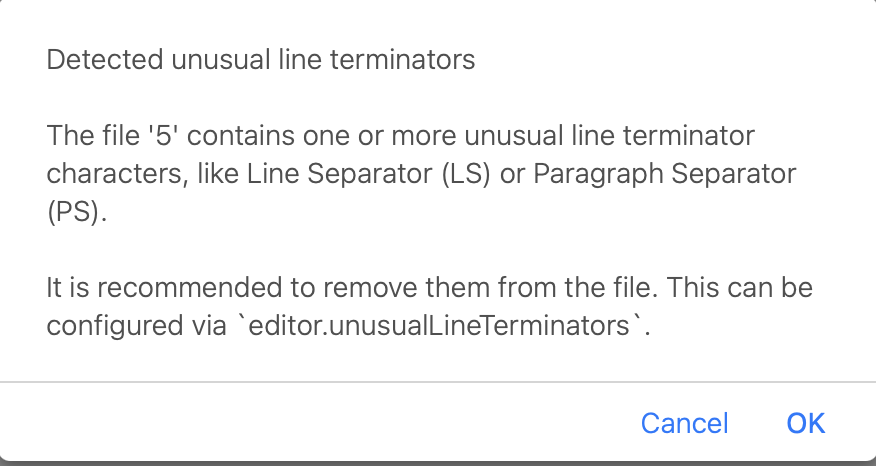
Another data point: the blog posts were created via the Add Page by Form plugin, and when I open one of the posts, I receive the following notification about “unusual line terminators”:
Not sure if that would make any difference, however.
Thanks again for your help!
Update: I cloned the site and …
- … disabled all plugins except for the Admin Panel: no difference.
Great! Probably no problems there.
- … deleted ~250 posts: immediate difference with site response time dropping from ~3000 ms to 300 ms.
This is odd, 25% less pages and 10 times faster response time… Maybe it has to do with the content of one or more of the deleted pages.
I guess you understand the aim is to find the problem page(s).
After trying 10 different iterations of which posts I delete, once I delete ~50 total posts, the site speeds up.
So it isn’t the specific files themselves, but the quantity of files. ![]()
But odd that reducing the number of total files from 1805 to 1740 would make that much of a difference.
Are you saying, that it doesn’t matter which 50 pages you delete, the result is the same? I mean if you delete 50 random pages 20 times, each of these 20 times it speeds up?
Correct …
Once I delete ~50 pages, the site speeds up — regardless of which pages those are.
@superhua, I’m sorry to say I have no more suggestions wrt Grav itself…
I’m not well versed on infra, but could it be that some limit for Apache, or OS have been hit?